Eager Loading and the N+1 Query Problem
Feb 4, 2021 • Kevin Gilpin
This is a special guest post from Kevin Gilpin of AppLand. Kevin reached out about an improvement to the Ruby on Rails Tutorial regarding an important type of database query optimization known as eager loading, which is the solution to a corresponding problem known as an “\( N+1 \) query”. I suggested he write up a post on the subject for the Learn Enough blog, and he happily agreed. I even updated the relevant section of the Rails Tutorial accordingly. Thanks to Kevin for the excellent contribution!
UPDATE: There’s now a video version narrated by Dan from AppLand!
Michael Hartl Author, the Ruby on Rails Tutorial
Working with any popular programming framework today typically means using an object-relational mapping (ORM) library like Rails’ Active Record to interact with the database. ORM systems are a definite plus for developer productivity and general happiness. They also allow a programmer to get by with a little bit less knowledge (sometimes a whole lot less) about what’s happening in between their code and the database. But that convenience comes with some pitfalls, including the common \( N+1 \) query problem. What does that mean? Read on to find out!
Working with an ORM
When we use an ORM library to load what our code calls an object (and the database calls a row),
providing the unique identifier (primary key) is sufficient to generate and execute the Structured Query Language (SQL) needed
to load our object data into memory. Similarly, we can update attributes on the object and then simply
save it. Once again, SQL is generated automatically by the ORM to save the changes to the database.
This is straightforward when working with a single row of data. But there are lots of places in our application
where we want to show data in lists, tables, graphs, etc. If we were writing that SQL by hand, we’d write a SELECT clause
to specify the columns we want and a WHERE clause that matches all the data we want to see. In this way, we’d grab the
entire table’s worth of data in one query. This batch retrieval is lot more efficient than querying the rows one at a time
using \( N \) queries for \( N \) rows.
Batch retrieval and associations
ORM systems have a couple of features to support batch retrieval. The first is accessor methods that allow the programmer
to specify the conditions of a WHERE clause and return multiple objects in an array, rather than just a single object. This feature makes it easy to find all rows that, for example, match a user-specified search term. The second (more complex) feature is associations. An association is a relationship (or, in database terms, a relation) between two types of
data.
A classic example of an association, which is used in the Rails Tutorial sample app, is users -> microposts -> attachments. The Rails
sample app requires all users to log in. Each user is represented in the database as a row in the users table. Once logged in, users can submit microposts (think of a micropost as a “tweet”). Each micropost can have an optional image attachment. In database terms, the relationship between users and microposts is one-to-many, and between microposts
and attachments is one-to-one. If an attachment could be shared by multiple microposts, then the relation would be
many-to-one.
Let’s take a look at how the ORM interacts with this schema in a common scenario: showing the microposts “feed” for a user consisting of the microposts of the user plus those of the other users being followed. Consider a controller that retrieves a page of microposts for this user:
@user.microposts.paginate(page: params[:page])
The ORM is smart enough to fetch one page of microposts in one batch, making the this operation simple and efficient… right? Not necessarily.
Pitfall – The N+1 query problem
When we look under the covers, there’s a problem.
Suppose the HTML page template that uses @microposts looks something like Listing 1.
- @microposts.each do |post|
%li
= post.body
%br
created by
= post.user.name
%ul
- post.attachments.each do |attachment|
%li
= attachment.url
(The code in Listing 1 uses the Haml syntax for representing HTML. Refer to the Haml documentation or use your technical sophistication to figure out the correspondence between Haml syntax and HTML tags.)
Using one of the techniques described in Box 1, we can observe the queries which are issued by this block of code. The first query that we see fetches the number of microposts for the user:
SELECT
COUNT(*)
FROM
"microposts"
WHERE
(user_id = ?)
Next, there’s a query to fetch a page of microposts:
SELECT
"microposts".*
FROM
"microposts"
WHERE
(user_id = 762146111)
ORDER BY
"microposts"."created_at" DESC
LIMIT ? OFFSET ?
The LIMIT and OFFSET are the query clauses that select the page offset and the page size. Note that an ORDER BY is always
required for pagination; otherwise, the OFFSET might not have the desired effect across multiple queries.
So far, so good.
But now there’s a problem. We see the two queries shown in Listing 2 and Listing 3 repeated many times—once for each micropost, in fact.
SELECT
"active_storage_attachments".*
FROM
"active_storage_attachments"
WHERE
"active_storage_attachments"."record_id" = ?
AND "active_storage_attachments"."record_type" = ?
AND "active_storage_attachments"."name" = ?
LIMIT
?
SELECT
"users".*
FROM
"users"
WHERE
"users"."id" = ?
LIMIT
?
What’s going on? What we are seeing here is known as the \( N+1 \) query problem. The number of queries to fetch the data is not \( 1 \), as we would expect; rather, it’s \( 1 \) to fetch the page of microposts, plus an additional \( N \) queries for the users, for a total of \( N+1 \). (In this case, there are an additional \( N \) queries for the user attachments, so the total is actually \( 2N+1 \), which is even worse.)
When SQL is hand-coded, a programmer has control over which queries are issued. The downside is that there can be a lot of repetitive and mundane work (as well as security risk) required to perform simple tasks of saving and loading data. ORMs relieve programmers of that work and risk, making development faster and more secure. But because queries are issued automatically, we cannot tell by looking at one section of the code—in this case, the HTML template—which queries will be executed behind the scenes. Changes to one part of the code could change the SQL behavior of virtually any other part of the code. That’s pretty tough to handle. So, what to do?
Figuring out what SQL your code is issuing can be tricky.
One useful tool is the mini_profiler Ruby gem. When you integrate and activate mini_profiler, it
displays a breakdown of the time spent in your backend code. You can click into
SQL for detailed timing of each query.
mini_profiler shows you all the queries, but it doesn’t show you which part of the code
is responsible for each query. For visual debugging of web services, code, and SQL
you can use the open-source
AppLand framework,
which consists of an open data format, data-recording clients, visualization libraries, and
IDE integrations such as the
AppMap extension for VSCode. The AppLand framework records the behavior of your code,
either from test cases or from user interaction. The AppLand IDE extension displays the recorded data as interactive
diagrams, graphs, tables, and visualizations. You can see exactly which function is
generating each query, and you can navigate all the way down to the Ruby code level if you want to.
Here’s an example:
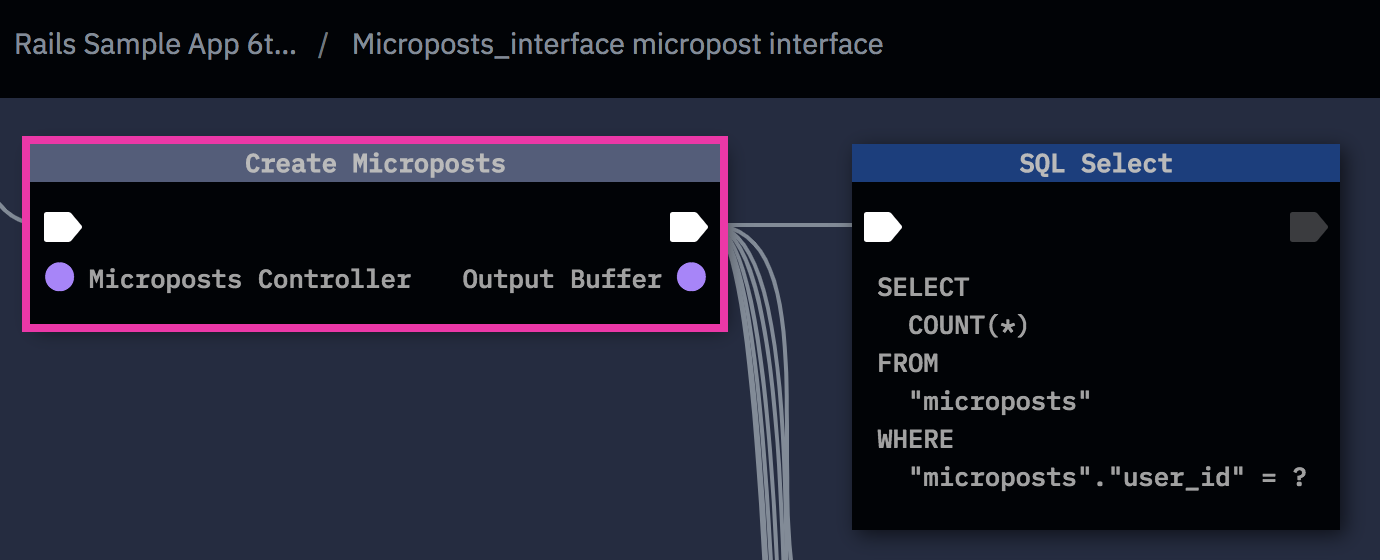
The fix
Fortunately, ORMs such as ActiveRecord do provide a way to fix this \( N+1 \) query problem. The solution is called eager loading. “Eager loading” is named to contrast with “lazy loading”, in which data is retrieved just-in-time as it’s needed. Lazy loading doesn’t refer to lazy programmers; it refers to lazy code. With lazy loading, the code takes the “lazy” approach of waiting until data is needed to load it. Unfortunately, in the example above, each micropost is lazy-loading its users and its attachments. The microposts aren’t “smart” enough to coordinate with each other and “lazy load” all the attachments at once—it’s every micropost for itself. The result is a slew of queries as each micropost loads its attachments and associated user.
Eager loading is a programmable option in which data associations are loaded “eagerly”, as in up-front, right now. The advantage of eager loading is that the ORM will be smart enough to use the eagerly loaded data when it’s needed.
More concretely, let’s look at an actual Active Record query from the Rails Tutorial sample app. Listing 4 shows the micropost feed from the User model.
app/models/user.rb
class User < ApplicationRecord
.
.
.
# Returns a user's status feed.
def feed
following_ids = "SELECT followed_id FROM relationships
WHERE follower_id = :user_id"
Micropost.where("user_id IN (#{following_ids})
OR user_id = :user_id", user_id: id)
end
.
.
.
end
What we want to do is turn this:
Micropost.where("user_id IN (#{following_ids})
OR user_id = :user_id", user_id: id)
into this:
Micropost.where("user_id IN (#{following_ids})
OR user_id = :user_id", user_id: id)
.includes(:user, image_attachment: :blob)
The includes clause is the key. As the Active Record documentation says, includes enables the programmer to:
specify relationships to be included in the result set… This will often result in a performance improvement over a simple join.
In this case, we’re using Active Record to create an underlying SQL query that includes both the associated user (via the symbol :user) and any image attachments (via image_attachment: :blob).
If we don’t need that extra data, then eager loading is a wasted effort, which is why Active Record doesn’t do it automatically. But if we do need it, the efficiency savings can be substantial.
Finding N+1 query bugs
Figuring out when we have an \( N+1 \) query problem is tricky, because it’s not the type of problem that’s revealed by any mainstream testing strategy. Unit tests, functional tests, and integration tests will all happily pass whether the data is being lazy-loaded or eager-loaded. Performance tests may reveal an issue, but a single \( N+1 \) query problem, while inefficient, does not generally result in a really big performance penalty. Rather, \( N+1 \) queries are sort of like an extra weight or drag on our app, slowly adding more and more inefficiency until, as a whole, our app is noticeably slowed down.
An effective way to find \( N+1 \) query problems is to look ar the number of SQL queries that are performed in a
realistic situation, such as an integration test, and compare this number with a “reasonable” expectation. Two tools, when combined together, will yield the query count for any test case in a straightforward way. These two tools are appmap-ruby and jq.
appmap-ruby
appmap is a Ruby gem that records the execution of code and writes it as a JSON file.
jq
jq is a lightweight and flexible command-line JSON processor. See the jq website for installation instructions on your system. (Mac users with Homebrew can install jq using brew install jq.)
appmap-ruby + jq
We can use the following procedure to count the number of SQL queries in a test case:
- Run the test case with
appmap-rubyenabled, which will create a JSON file containing the recorded code events. - Process the recorded code events through
jqto count the number of SQL queries.
The steps below show how to update a generic Rails app with these tools. If you’d like to follow along with a concrete example, you can clone the Rails Tutorial sample app, follow the setup steps described in the README, and then check out the eager-loading branch:
$ git clone https://github.com/mhartl/sample_app_6th_ed.git
$ cd sample_app_6th_ed
$ git checkout eager-loading
The eager-loading branch of the reference app adds the appmap gem to its Gemfile, as shown in Listing 5.
appmap gem to the sample app. Gemfile
,
,
,
group :development, :test do
gem 'sqlite3', '1.4.2'
gem 'byebug', '11.1.3', platforms: [:mri, :mingw, :x64_mingw]
gem 'appmap', '0.40.0'
end
.
.
.
To install the new gem, run bundle install as usual:
$ bundle install
A second change, already implemented in the reference app, is the addition of a YAML configuration file to be used by appmap-ruby, which appears as in Listing 6.
appmap.yml
name: SampleApp
packages:
- path: app/controllers
- path: app/models
- gem: activerecord
Taking the steps shown above one at a time, the first step is to record a test case. Let’s suppose we have an integration
test like microposts_interface_test.rb. Run the test with APPMAP=true:
$ APPMAP=true bundle exec ruby -Ilib -Itest \
test/integration/microposts_interface_test.rb
Because the sample app’s test_helper.rb file has been configured as described in the appmap minitest documentation, this test will automatically create a file called
tmp/appmap/minitest/Microposts_interface_micropost_interface.appmap.json
To get some insight into the application’s behavior, we can process this file through the jq query shown in Listing 7, which:
- Enumerates all the code events that occurred during the test case. Code events include HTTP server requests, function calls, and SQL queries.
- Selects just those code events that are SQL queries.
- Counts the number of queries.
jq.
$ jq '[.events[] | select(has("sql_query"))] | length' \
tmp/appmap/minitest/Microposts_interface_micropost_interface.appmap.json
237
237 queries is a lot for one test case!1 I’ve recorded all of the 66 test cases in the Rails Sample App 6th Edition, and plotted the number of SQL queries in each test case as a histogram (Figure 1).
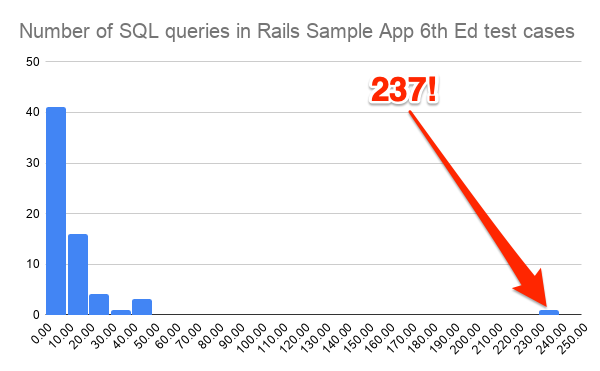
That 237 in Figure 1 really sticks out. Next, I have applied the eager loading fix and re-run the test cases. The number of queries drops to 72, as shown in Figure 2.
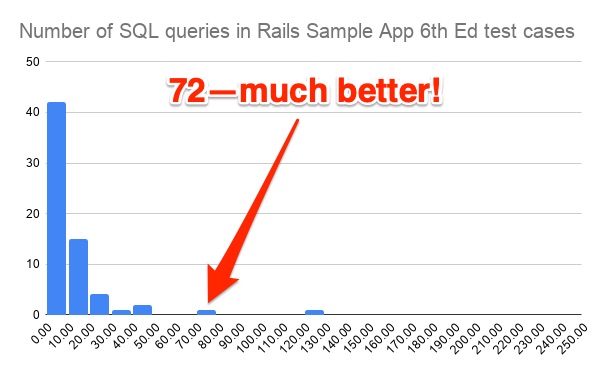
It’s still quite a few; maybe there is more room for optimization? I will leave that as an exercise for the reader!
(By the way, you may have noticed in Figure 2 that one of the query counts, around 120, is actually worse after being “optimized”. This is because there is a test case in the sample app, "feed should have the right posts", that loops through the posts of each of four users and checks that the user’s
feed includes the post. The number of queries in this test is actually
increased by adding eager loading because fetching a feed now takes three
queries instead of one. But this is really an artificial scenario: the app
itself never fetches \( N\times M \) feeds, and when it does fetch a feed it renders
it in the view, which traverses the associations and hence benefits from eager loading.)
Verifying the fix
Once you have tuned the ORM and queries, you can add an assertion to your test case that will verify the query count. In one unoptimized test case in the Rails Sample App 6th Edition, a page issues over 100 SQL queries:
require 'test_helper'
class MicropostsInterfaceTest < ActionDispatch::IntegrationTest
.
.
.
test "micropost interface" do
.
.
.
# Valid submission
content = "This micropost really ties the room together"
image = fixture_file_upload('kitten.jpg', 'image/jpeg')
assert_difference 'Micropost.count', 1 do
post microposts_path, params: { micropost: { content: content,
image: image } }
end
assert assigns(:micropost).image.attached?
follow_redirect!
assert_match content, response.body
.
.
.
end
end
With eager-loading optimization applied, the page issues under 100 queries. What we’d like is a test that will fail if the query count goes over this limit, thereby catching any regressions.
To make the test, we can use the assert_operator minitest assertion, which lets us assert that one number is less than another using the symbol :< to represent the “less than” operator:
assert_operator 50, :<, 100
This would assert the relationship 50 < 100, which would pass because the statement is true.
The actual query happens upon redirecting after successful submission, which renders the feed on the user’s home page, so we can wrap the redirect in a block that uses appmap to make a list of events associated with the newly rendered page:
events = AppMap.record do
follow_redirect!
end['events'].map { |event| OpenStruct.new(event) }
(This code is a little advanced, so don’t worry too much about the details. Try putting p events somewhere after the code above if you’d like to see what the events variable looks like in this case.)
Using the select method to select SQL query events then looks like this:
sql = events.select(&:sql_query)
Knowing how to do this involves reading a bit of the appmap documentation or using the p trick above to figure out what the internals of the event array look like.2
We can then test that the number of queries is less than 100 using assert_operator:
assert_operator sql.count, :<, 100
Putting everything together gives the test shown in Listing 8.
test/integration/microposts_interface_test.rb
require 'test_helper'
class MicropostsInterfaceTest < ActionDispatch::IntegrationTest
def setup
@user = users(:michael)
end
test "micropost interface" do
.
.
.
assert assigns(:micropost).image.attached?
events = AppMap.record do
follow_redirect!
end['events'].map { |event| OpenStruct.new(event) }
sql = events.select(&:sql_query)
# Without the eager-loading optimization, > 100 queries are issued here.
assert_operator sql.count, :<, 100
assert_match content, response.body
.
.
.
end
end
Running the tests with the default status feed (without eager loading) should then give us a red test suite:
$ rails test
66 tests, 344 assertions, 1 failures, 0 errors, 0 skips
To get the test to green, we can update the feed method in the User model with eager loading, as shown in Listing 9.
app/models/user.rb
class User < ApplicationRecord
.
.
.
# Returns a user's status feed.
def feed
following_ids = "SELECT followed_id FROM relationships
WHERE follower_id = :user_id"
Micropost.where("user_id IN (#{following_ids})
OR user_id = :user_id", user_id: id)
.includes(:user, image_attachment: :blob)
end
.
.
.
end
With the eager loading added as in Listing 8, the test suite should be green:
$ rails test
66 tests, 349 assertions, 0 failures, 0 errors, 0 skips
Great! Now our test suite will tell us immediately if eager loading ever stops working for some reason or is accidentally removed. (It’s worth noting that the exact number of SQL queries can be system-dependent, which can lead to spurious test failures. For production systems, it’s a good idea to avoid this issue by using a standard test environment at a continuous-integration service like Travis CI or Circle CI.)
In conclusion
ORMs are powerful. With great power comes great responsibility, and in this case, it’s a responsibility to keep an eye on what that ORM is doing under the covers. It’s very easy to accidentally introduce an \( N+1 \) query problem, because all a developer needs to do is traverse a new object relationship in a view, and a separate SQL query for each object can be triggered.
In this blog post, you’ve learned what the \( N+1 \) query problem is, how to fix it with eager loading, and how to add a test case to verify that the fix is working. That should be everything you need to tackle this thorny problem. Good luck!
2. The p <var> method is just an alias for puts <var>.inspect, so p is a convenient way to view the contents of things like arrays or hashes by printing literal versions to the screen:
$ irb
>> a = [1, 2, 3]
>> puts a
1
2
3
>> p a
[1, 2, 3]