Everyone Should Learn the Command Line
Aug 7, 2019 • posted by Michael Hartl
Learning to code? Learn Enough is based on the idea that you don’t have to learn everything about tech to get started—you just have to learn enough to be dangerous. This is the first in a series of posts introducing the main Learn Enough tutorials. You can find the second one here. You might also enjoy the Learn Enough Command Line free sample chapters and free sample videos.
Learn Enough Command Line
The first Learn Enough tutorial is Learn Enough Command Line to Be Dangerous, which covers the Unix command line, a text-based interface for interacting with computers. The command line is so important that I think pretty much everyone should learn to use it—or, at least, everyone who works with software developers, including those who aspire to become developers themselves.
When we first started making the Learn Enough tutorials a few years ago, I initially thought I would begin by making a tutorial on text editors, a class of application used for editing so-called “plain text”. Then I realized that I and pretty much everyone I knew usually launched a text editor from the command line, which meant that had to come first.
The more I thought about it, the clearer it became that I had to start with the command line, because it lies at the foundation of so much else in tech. But, bizarrely, I couldn’t find a single command-line tutorial that didn’t assume that you already knew lots of other things (including, in many cases, a text editor).
Thus Learn Enough Command Line to Be Dangerous was born. It assumes no prerequisites other than general computer knowledge, while also being a great way to review the basics for those more experienced with tech.
Like all the Learn Enough tutorials, Learn Enough Command Line to Be Dangerous comes as a book (90 pages), as videos (1¼ hours), and as a self-paced online course (including all the book and video content, plus 67 exercises and several other features).
Powerful and cool
In order to introduce some of the cooler and more powerful aspects of the command line, I decided to make a short video showing one of the actual commands I ran in the course of developing the newly designed Learn Enough home page.
In order to reach the requisite level of cool, I had to choose commands that are a little bit more advanced than those in beginning of the tutorial. Rest assured, though, that Learn Enough Command Line to Be Dangerous truly starts at the beginning, building up gradually to the kinds of commands shown in the video (as you can see for yourself in the free first chapter).
Here’s the video in case you’d like to watch it now:
The video shows how to perform a fairly sophisticated calculation quickly and easily:
count the number of exercises in the full Learn Enough Command Line tutorial book
I wanted this statistic so that I could include the total number of exercises on the Command Line product page.
The text for the tutorial chapters is in the chapters/ directory of the book’s source on my computer, with one file for each chapter. We can see the names of all the chapters using the ls (“list”) command combined with the * character (asterisk, usually read as “star”), which is a so-called wildcard that matches any file name:1
$ ls chapters/*
basics.tex directories.tex inspecting_files.tex manipulating_files.tex
The source of, say, inspecting_files.tex looks something like Listing 1.2
,
,
,
On the other hand, you might get the feeling that it's a little unclean to make an intermediate file just to run \kode{wc} on it, and indeed there's a way to avoid it using a technique called \emph{pipes}. Listing~\ref{code:head_pipe} shows how to do it.
\begin{codelisting}
\label{code:head_pipe}
\codecaption{Piping the result of \kode{head} through \kode{wc}.}
%= lang:console
\begin{code}
$ head sonnets.txt | wc
10 46 294
\end{code}
\end{codelisting}
,
,
,
The video shows how to use the less command to search the source text for exercises; it turns out that each exercise is uniquely identified by a label that starts with the string of characters id="ex, as seen in Listing 2.
\begin{enumerate}
\item By piping the results of \kode{tail sonnets.txt} through \kode{wc}, confirm that (like \kode{head}) the \kode{tail} command outputs 10 lines by default.
%= <span class="exercise" id="ex-tail-wc"></span>
\item By running \kode{man head}, learn how to look at the first \kode{n} lines of the file. By experimenting with different values of \kode{n}, find a \kode{head} command to print out just enough lines to display the first sonnet in its entirety (Figure~\ref{fig:sonnet_1}).
%= <span class="exercise" id="ex-head-n"></span>
Because this pattern occurs exactly once per exercise, we can use the powerful grep command 3 to search through all the files for the given string (Listing 3).
grep to find every exercise label.
$ grep 'id="ex' chapters/*
<lots of output>
I’ve indicated with <lots of output> that the result is lots of output—one line, in fact, for each exercise. This means that, if we could just count how many lines there are, we would know how many exercises there are.
Happily, the command line comes with a tool for just this case. It’s called “wordcount”, or wc for short.
We can arrange to run the output of grep from Listing 3 through wc using a powerful technique called “piping”, which uses the pipe character |. This character, though rarely used in everyday life, is often important in technical contexts, and can be produced on many keyboards using Shift-backslash, as shown in Figure 1.

| (“pipe”) character with Shift-backslash.
The result of piping the output of grep to wc appears in Listing 4.
grep and wc to count the number of exercises.
$ grep 'id="ex' chapters/* | wc
67 268 5534
The first number in the output of Listing 4—namely, 67—is the number of lines, so that means there are exactly 67 exercises in the full tutorial.4 This in turn is the number that gets shown on the product page (Figure 2).

Just think of how much work it would have taken to go through the entire tutorial and count every exercise! Not to mention that such a task would be terribly error-prone, and incredibly unlikely to get the right result. And yet, using the power of the command line, we can perform this important task in a single line using just two commands.
The incredible ubiquity of the command line
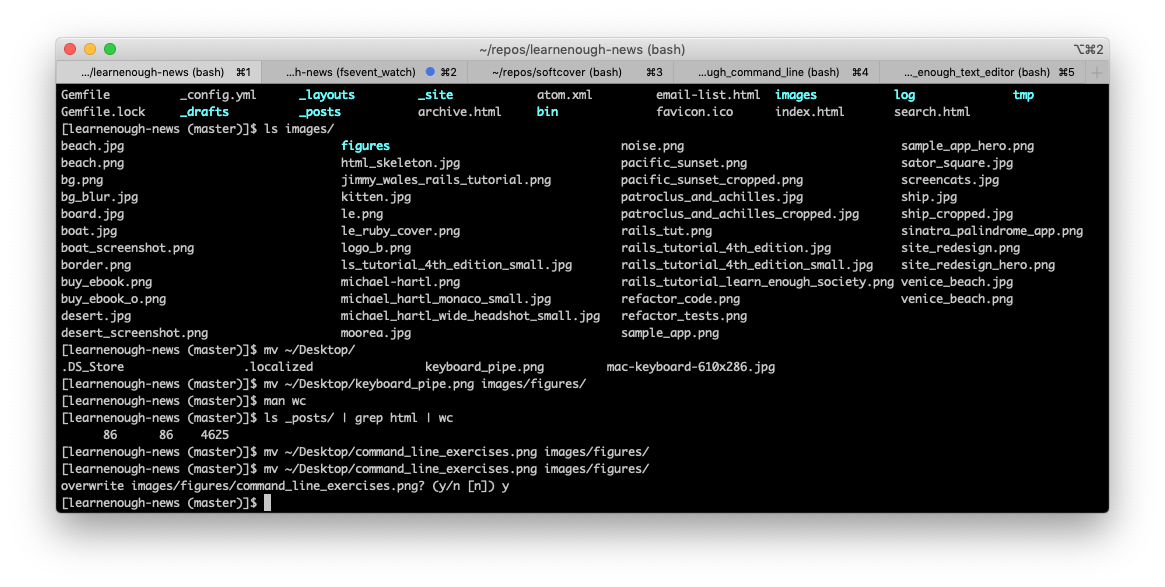
It’s really hard to emphasize how ubiquitous the command line is in the lives of most modern software developers. I used it a dozen times in the process of making this post alone (Figure 3).

Here are just a few of the commands launched from the command line in the course of the Learn Enough tutorials and the Ruby on Rails Tutorial:
echo,ls,cat,curlrm,mv,cp,cdtouchopengit init,git add,git commitjekyll servenoderubyrails new,rails server,rails console
Because it’s used for so many different things, the command line can be considered one of the defining tools for “technical” people. As a result, a basic familiarity with the command line is beneficial for anyone who works with technical people as well.
In other words, there’s simply no substitute for learning how to use the command line. And Learn Enough Command Line to Be Dangerous is designed to be the best place to start.
Questions or comments? Hit us up at @LearnEnough on Twitter!
*—the ls command will list all directory contents by default—but I include it here both for completeness and because it’s actually required in Listing 3.grep actually stands for something, but it’s not important what—most people who use grep have no idea what it means. Learning to ignore these sorts of irrelevant details is an important part of a skill called technical sophistication.